판다스는 2차배열을 DataFrame 함수를 통해 만들수 있다.
DataFrame을 만들기전 먼저 딕셔너리 형태로 판다스 1차배열인 Serise들을 묶어 변수로 지정해주면 2차 배열인 데이터프레임을 쉽게 만들수 있다.
in:
# We create a dictionary of Pandas Series
items = {'Bob' : pd.Series(data = [245, 25, 55], index = ['bike', 'pants', 'watch']),
'Alice' : pd.Series(data = [40, 110, 500, 45], index = ['book', 'glasses', 'bike', 'pants'])}df = pd.DataFrame(data=items)
df
out:
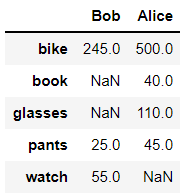
# 왼쪽 진한글자는 인덱스
# 위쪽 진한글자는 컬럼
# 안에있는 데이터는 벨류
#전체는 데이터프레임이라 부른다.
데이터 프레임은 1차배열인 시리즈와 마찬가지로 index와 values함수를 통해 인덱스와 밸류들을 볼수있고
추가적으로 columns 함수를 통해 컬럼명을 볼수있다.
in:
print(df.index)
print(df.values)
print(df.columns)out:
Index(['bike', 'book', 'glasses', 'pants', 'watch'], dtype='object')
[[245. 500.]
[ nan 40.]
[ nan 110.]
[ 25. 45.]
[ 55. nan]]
Index(['Bob', 'Alice'], dtype='object')
데이터프레임 속 NaN은 'Not a Number'이며 해당 항목에 값이 없음을 뜻한다.
NaN은 실제로 아래와 같다
in:
np.nannan
csv(comma separated values)로 처리하는 방법 :
1. 먼저 (대표적으로)메모장 실행시켜 콤마로 구분된 2차배열 형식의 표를 만든다.
#csv 맨위의 행은 컬럼명을 적어야 한다.
2. 파일 저장시 모든파일 옵션으로 전환후 확장자 명으로 .csv를 입력하여 저장한다.
3. 파이썬으로 돌아와서 read_csv 함수를 실행시켜 배열을 불러온다.
in:
df = pd.read_csv('my_test.csv')
dfout:
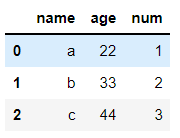
※ 간혹 'Unnamed: 0' 이라는 컬럼이 나올수 있는데 이때 마지막 파라미터에 index_col = 0을 입력하면 해결된다.
4. to_csv 함수로 작업중이던 데이터들을 다른이름으로 저장한다. (save 아님)
df.to_csv('my_test2.csv')# 저장하지 않고 종료하면 데이터가 사라지니 주의하자
0부터 시작하는 인덱스 명을 사용자가 원하는 명칭으로 바꿔줄수 있다.
데이터 파라미터의 값만 만족시킨경우 인덱스가 0으로 시작하게 된다.
in:
items2 = [{'bikes': 20, 'pants': 30, 'watches': 35},
{'watches': 10, 'glasses': 50, 'bikes': 15, 'pants':5}]
pd.DataFrame( data= items2)
df = pd.DataFrame( data= items2)
dfout:
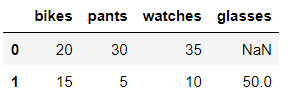
데이터프레임을 만들때 인덱스 파라미터를 설정해 인덱스 명칭을 생성해보자.
in:
df = pd.DataFrame( data= items2, index= ['store 1','store 2'])
dfout:
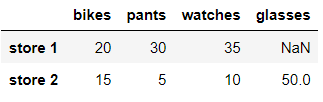
데이터프레임에서 데이터 억세스 하는방법은 여러가지가 있다.
1. 대괄호로 컬럼 데이터 가져와서 데이터 억세스
in:
df['bikes']out:
store 1 20
store 2 15
Name: bikes, dtype: int64# 두개 이상의 데이터를 가져오고싶을때 대괄호 ' [ ] ' 로 감싸서 억세스 한다.
2. 인덱스 명칭과 컬럼명으로 데이터 억세스 ( .loc[인덱스 , 컬럼명] )
in:
df.loc[ 'store 1', 'pants' ]out:
30# 항상 대괄호 안의 콤마를 기준으로 행(row)과 열(column)이 나뉜다는것을 인지해야 한다.
3. 컴퓨터가 자동으로 매기는 인덱스로 행열 가져오기
in:
df.iloc[0,1]out:
30
데이터프레임의 데이터값을 변경해보자.
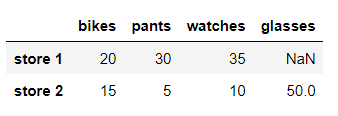
store 2 의 watches 값을 20으로 변경한다면
in:
df.loc['store 2','watches']=20
dfout:
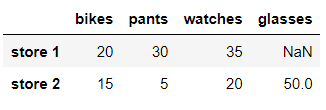
# loc함수를 이용해 데이터를 변경했다.
새로운 컬럼을 생성할수 있다.
shirts 컬럼을 생성해보자 (스토어1: 15개, 스토어2: 2개)
in:
df['shirts'] = [15,2]
dfout:
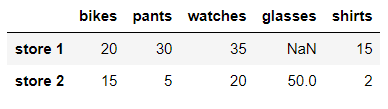
# 새로운 컬럼의 값을 리스트로 묶어 지정했다.
pants컬럼과 shirts컬럼 합쳐서 suits컬럼 만드려고 할때
in:
df['suits'] = df['pants']+df['shirts']
dfout:
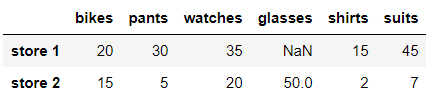
새로운 행을 데이터프레임에 추가해보자
먼저 새로운 행을 만들고
in:
new_item = [{'bikes':20,'pants':30,'watches':35,'glasses':4}]
new = pd.DataFrame(new_item, index=['store 3'])
newout:
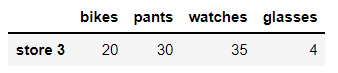
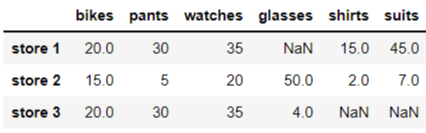
append 함수를 이용해 데이터를 추가한다.
in:
df = df.append(new)
dfout:
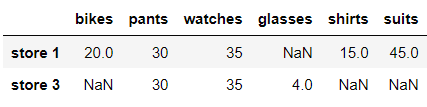
drop 함수로 데이터를 제거할수 있다.
스토어 2 행을 제거해보자
in:
df.drop('store 2', axis= 0)out:
# 파라미터를 추가하여 inplace= True를 입력하면 원본 데이터프레임에 바로 적용할수 있다.
# axis 값이 0이면 행단위로 삭제할수있고, 1이면 열단위로 삭제할수 있다.
# 삭제하고 싶은 행 혹은 열이 두개 이상이면 대괄호로 묶어서 입력하면 된다.
rename함수를 사용해 인덱스 또는 컬럼명을 변경할수있다.
bikes를 hats으로 바꾸고 suits를 shoes로 바꾸자
in:
df.rename(columns={'bikes':'hats','suits':'shoes'})out:
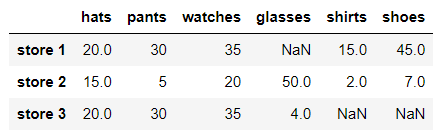
# 파라미터에 columns으로 하면 컬럼명을 , index로 하면 인덱스를 바꿀수있다.
set_index함수로 name이라는 컬럼을 새로 만들어 인덱스로 변경해보자
in:
df['name']=['A','B','C']
df.set_index('name')out:
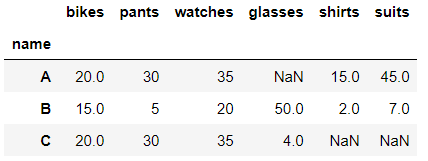
# 원본 데이터프레임에 저장했다가 다시 인덱스를 원상태로 돌리고 싶다면 reset_index 함수를 사용하면 된다.
'Python' 카테고리의 다른 글
| [파이썬] 판다스: 카테고리컬 데이터 (categorical data) (0) | 2022.05.01 |
|---|---|
| [파이썬] 판다스: NaN (0) | 2022.04.29 |
| [파이썬] 판다스: 1차 배열, Series (0) | 2022.04.28 |
| [파이썬] 넘파이: 인덱스, 슬라이싱, delete, append, insert, copy, unique (0) | 2022.04.28 |
| [파이썬] 넘파이: array, size, shape, dtype, save, load, zeros, ones, full, arange, linspace, reshape, ndim, argmax (0) | 2022.04.27 |



댓글