[파이썬] 영화 추천 시스템 실습: Item-based Collaborative Filtering, pivot_table, corrwith
추천시스템은 영화나 노래등을 추천하는데 사용되며, 주로 관심사나 이용 내역을 기반으로 추천한다.

실습 1. 두개의 데이터프레임을 합치시오.
in:
movie = pd.merge(movies_rating_df,movie_titles_df, on = 'item_id')out:

실습 2. timestamp 컬럼은 필요없으니, movies_rating_df 에서 아예 제거하시오.
in:
movie.drop('timestamp',axis=1,inplace=True)
movieout:

실습 3. 각 영화별 별점의 평균을 구하고, 이를 ratings_df_mean 에 저장하시오.
또, 각 영화별로 몇개의 데이터가 있는지 구하고, 이를 ratings_df_count 에 저장하시오.
ratings_df_mean = movie.groupby('title')['rating'].mean()
ratings_df_count = movie['title'].value_counts()
실습 4. 위의 두 데이터프레임을 합치세요.
in:
mc_df = pd.merge(ratings_df_mean,ratings_df_count,on='title')
mc_df.rename(columns={'rating':'mean'},inplace = True)
mc_dfout:

# 컬럼명을 rename함수를 사용하여 정리해줬다.
실습 5. 피봇 테이블을 하여, 콜라보레이티브 필터링 포맷으로 변경하시오
in:
df = movie.pivot_table(values='rating',index='user_id',columns='title',aggfunc='mean')out:

# pivot_table 함수를 사용했다
# values 파라미터에 별점을 넣고 인덱스를 유저 id로 설정했다.
# 컬럼은 영화 제목으로 설정했고 aggfunc을 mean으로 설정하여 평균값이 나오도록 했다.
실습 6. 전체 영화와, 스타워즈 영화의 상관관계 분석을 하시오
corrwith 함수를 사용하여 스타워즈를 본 사람들에게 상관계수의 유사도가 높은 영화를 추천하면 된다.
먼저 유저들의 스타워즈에 대한 별점을 뽑아본다.
in:
df['Star Wars (1977)']out:
user_id
0 5.0
1 5.0
2 5.0
3 NaN
4 5.0
...
939 NaN
940 4.0
941 NaN
942 5.0
943 4.0
Name: Star Wars (1977), Length: 944, dtype: float64
그 후, corrwith함수를 사용하여 전체 영화와 스타워즈 영화의 상관관계를 구한다.
in:
starwars_corr = df.corrwith(df['Star Wars (1977)'])
starwars_corrout:
title
'Til There Was You (1997) 0.872872
1-900 (1994) -0.645497
101 Dalmatians (1996) 0.211132
12 Angry Men (1957) 0.184289
187 (1997) 0.027398
...
Young Guns II (1990) 0.228615
Young Poisoner's Handbook, The (1995) -0.007374
Zeus and Roxanne (1997) 0.818182
unknown 0.723123
Á köldum klaka (Cold Fever) (1994) NaN
Length: 1664, dtype: float64# df(전체영화)에 함수를 사용하고 파라미터로 df['Star Wars (1977)'] (스타워즈) 를 적용시켰다.
이제 구한 값들을 상관계수를 나타내는 컬럼으로 정하고 카운트 컬럼을 합친다.
in:
starwars_corr = starwars_corr.to_frame()
starwars_corr.columns = ['correlation']
starwars_corr = starwars_corr.join(mc_df['count'])
starwars_corr.dropna(inplace=True)
starwars_corr.loc[starwars_corr['count']>80,].sort_values('correlation',ascending=False)out:

# 먼저 데이터 프레임으로 바꾸고 컬럼명을 적절히 바꿔줬다.
# 그 후 count 데이터를 join해주고 Nan처리해줬다.
# 리뷰개수가 80이상인 영화들만으로 추려서 상관계수를 기준으로 내림차순으로 정렬했다.
실습 7. 유저의 별점 정보를 가지고, 영화를 추천 하시오
myRatings=

101마리 달마시안 영화와 높은 상관계수를 갖고있는 영화를 추천하자.
먼저 최소 관측치 수가 80개 이상인 데이터만 뽑아보자
in:
movie_corr = df.corr(min_periods=80)
movie_corr.head(3)out:

# 피봇테이블인 df에 corr를 적용시킨 후 min_periods 파라미터를 통해 최소 관측치 수가 80개 이상의 데이터를 뽑아 대중성 높은 영화들을 가져왔다.
이제 101마리 달마시안의 상관계수를 뽑아 추천 영화들을 골라낸다.
in:
movie_name = myRatings['movie name'][1]
recom_movies = movie_corr[movie_name].dropna().sort_values(ascending = False)
recom_moviesout:

# 상관계수를 구한 뒤, Nan을 없애고 내림차순으로 정렬했다.
이제 가중치를 추가하자.
in:
recom_movies - recom_movies.to_frame()
recom_movies.columns = ['correlation']
recom_movies['weight'] = myRatings['rating'][1]*recom_movies['correlation']
recom_moviesout:

# 데이터프레임으로 변환 후, correlation 컬럼으로 만들고 101마리의 달마시안에 준 별점을 correlation 컬럼에 곱하여 가중치를 구했다.
실습 8. 위의 추천영화 작업을 자동화 하기 위한 파이프라인을 만드시오.
in:
similar_movies_list = pd.DataFrame()
for i in range(myRatings.shape[0]):
movie_name = myRatings['movie name'][i]
recom_movies = movie_corr[movie_name].dropna().sort_values(ascending= False).to_frame()
recom_movies.columns = ['correlation']
recom_movies['weight'] = myRatings['rating'][i] * recom_movies['correlation']
similar_movies_list = similar_movies_list.append(recom_movies)
similar_movies_listout:

# 유저가 본 모든 영화가 적용된 추천 영화 리스트가 완성되었다.
이제 내림차순으로 정렬하고 유저가 본 영화는 이 데이터프레임에서 삭제하자.
in:
similar_movies_list = similar_movies_list.sort_values('weight',ascending=False)
drop_index = myRatings['movie name'].to_list()
for name in drop_index:
if name in similar_movies_list.index:
similar_movies_list.drop(name,axis = 0, inplace=True)out:
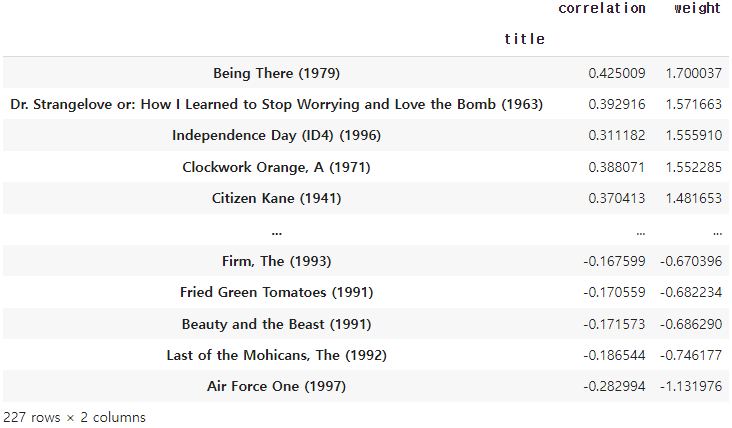
# 반복문을 사용하여 유저가 본 영화를 삭제했다.
중복된 영화가 있을경우 레이트가 가장 높은값으로만 추천하자
in:
similar_movies_list.groupby('title')['weight'].max().sort_values(ascending= False)out:
