머신러닝
[머신러닝] Hierarchical Clustering
eyoo
2022. 5. 10. 10:01
하이어라키컬 클러스터링은 각 데이터간의 거리가 가장 가까운것부터 묶어 순차적으로 클러스터링한다.
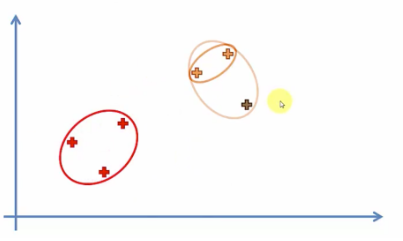
또한 이를 관계도인 덴드로그램을 통해 나타낼수 있다.
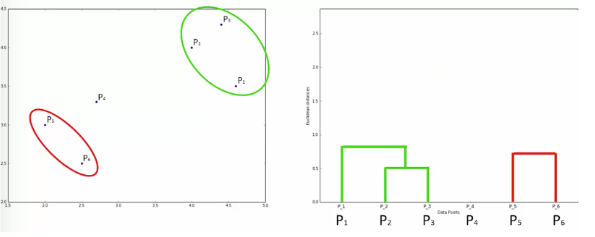
완성된 덴드로그램을 분석하여 사용자가 데이터를 몇개의 그룹으로 나눌지 결정한다.

# 주로 거리가 긴 (관계가 먼) 곳을 기준으로 나눠준다.
df=

먼저 X값을 정한다.
X = df.iloc[:,3:]
그 후, sch.dendrogram함수와 sch.linkage함수를 사용하여 덴드로그램을 그린다.
in:
sch.dendrogram(sch.linkage(X,method='ward'))
plt.title('Dendrogram')
plt.xlabel('Customers')
plt.ylabel('Eculidean Distance')
plt.show()out:

# 덴드로그램을 보니, 그룹개수는 5개가 적당한것 같다.
덴드로그램을 사용하여 결정한 그룹의 수로 하이어라키컬 클러스터링 해보자
from sklearn.cluster import AgglomerativeClustering
hc = AgglomerativeClustering(n_clusters=5)
결과를 데이터프레임의 그룹 컬럼으로 추가한다.
in:
y_pred = hc.fit_predict(X)
df['Group'] = y_pred
dfout:

그루핑 정보를 차트로 확인하자.
in:
plt.scatter(X.values[y_pred == 0, 0], X.values[y_pred == 0, 1], s = 100, c = 'red', label = 'Cluster 1')
plt.scatter(X.values[y_pred == 1, 0], X.values[y_pred == 1, 1], s = 100, c = 'blue', label = 'Cluster 2')
plt.scatter(X.values[y_pred == 2, 0], X.values[y_pred == 2, 1], s = 100, c = 'green', label = 'Cluster 3')
plt.scatter(X.values[y_pred == 3, 0], X.values[y_pred == 3, 1], s = 100, c = 'cyan', label = 'Cluster 4')
plt.scatter(X.values[y_pred == 4, 0], X.values[y_pred == 4, 1], s = 100, c = 'magenta', label = 'Cluster 5')
plt.title('Clusters of customers')
plt.xlabel('Annual Income (k$)')
plt.ylabel('Spending Score (1-100)')
plt.legend()
plt.show()out:
