[머신러닝] 전처리 과정 (Data preprocessing): NaN 처리, Label Encoding, One-hot Encoding, Feature Scaling, train_test_split
머신러닝은 말그대로 컴퓨터를 학습시키는 과정이다.
학습시키기 위해 컴퓨터가 학습할수 있도록 데이터를 변환하는 과정을 전처리 과정이라 한다.
전처리 과정을 시작하기 위해 sklearn을 사용해야한다.
만약 설치되지 않았다면 다음으로 설치한다:
$ conda install -c conda-forge scikit-learn
먼저 전처리할 (머신러닝에 필요한) 데이터를 불러온다.
in:
df = pd.read_csv('data/Data.csv')
dfout:
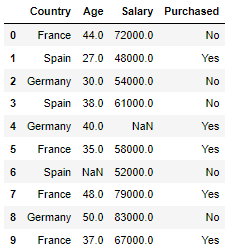
NaN 값이 있는지 확인 후 처리한다.
in:
df.isna().sum()out:
Country 0
Age 1
Salary 1
Purchased 0
dtype: int64
in:
df = df.dropna()
dfout:
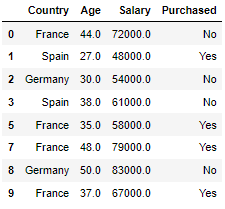
# NaN을 drop 할수도있고 다른값으로 변환할수도있다.
그 후 X, y데이터로 분리한다.
학습할 변수와 레이블링 변수로 분리하는 과정이다.
in:
X = df.loc[:,'Country':'Salary']
Xout:
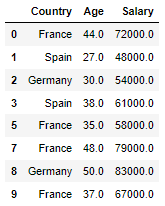
# 학습할 변수 X
in:
y = df['Purchased']
yout:
0 No
1 Yes
2 No
3 No
5 Yes
7 Yes
8 No
9 Yes
Name: Purchased, dtype: object# 레이블링 변수 y
문자로 되어있는 데이터는 방정식에 대입할수 없다.
따라서 문자를 숫자로 바꿔줘야 한다.
그 방법은:
- 먼저 해당 컬럼이 카테고리컬 데이터인지 확인한 뒤
- 카테고리컬 데이터면 데이터를 먼저 정렬한다.
- 정렬 후의 문자열을 앞에서부터 0으로 하나씩 숫자를 매긴다.
이 방법을 인코딩(encoding) 이라 하며,
숫자를 차례대로 매기는 레이블인코딩과
카테고리컬 데이터의 수만큼 배열을 만들어 해당 데이터에만 1을 넣어주는 원 핫 인코딩이 있다.
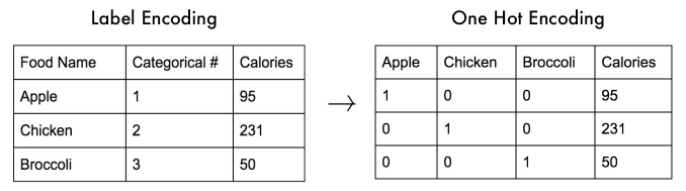
# 카테고리컬 데이터가 3개이상일때 레이블 인코딩으로 학습시키면 학습이 잘 안된다.
# 따라서 3개이상의 카테고리컬 데이터는 one-hot encoding (원 핫 인코딩) 을 이용해야 성능이 좋아진다.
unique 함수를 사용하여 country 열에 있는 카테고리컬 데이터는 총 몇개있는지 확인해보자
in:
X['Country'].unique()out:
array(['France', 'Spain', 'Germany'], dtype=object)# France, Spain, Germany 이렇게 총 3개가 있다.
먼저 인코딩에 필요한 라이브러리를 임포트 하자
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.compose import ColumnTransformer
레이블 인코딩 하는 방법:
in:
encoder = LabelEncoder()
encoder.fit_transform(X['Country'])out:
array([0, 2, 1, 2, 0, 0, 1, 0])# 카테고리컬 데이터가 세개라서 문자의 오름차순대로 0,1,2로 표시가 된다.
# 이때는 레이블 인코딩 보다는 원핫 인코딩을 활용하는게 더 낫다.
y를 레이블 인코딩으로 변환시켜보자
in:
encoder_y=LabelEncoder()
y = encoder_y.fit_transform(y)
yout:
array([0, 1, 0, 0, 1, 1, 0, 1])
원핫 인코딩 하는법:
in:
ct = ColumnTransformer( [ ('encoder',OneHotEncoder(), [0] ) ] , remainder='passthrough' )
X = ct.fit_transform(X)
Xout:
array([[1.0e+00, 0.0e+00, 0.0e+00, 4.4e+01, 7.2e+04],
[0.0e+00, 0.0e+00, 1.0e+00, 2.7e+01, 4.8e+04],
[0.0e+00, 1.0e+00, 0.0e+00, 3.0e+01, 5.4e+04],
[0.0e+00, 0.0e+00, 1.0e+00, 3.8e+01, 6.1e+04],
[1.0e+00, 0.0e+00, 0.0e+00, 3.5e+01, 5.8e+04],
[1.0e+00, 0.0e+00, 0.0e+00, 4.8e+01, 7.9e+04],
[0.0e+00, 1.0e+00, 0.0e+00, 5.0e+01, 8.3e+04],
[1.0e+00, 0.0e+00, 0.0e+00, 3.7e+01, 6.7e+04]])# 원핫 인코딩할 데이터의 컬럼이 0자리에 있기 때문에 [ ]에 인덱스 값 0을 입력했다.
# 만약 원핫 인코딩할 컬럼이 두개면 해당 컬럼의 인덱스를 리스트안에 '[ ]' 적어주면된다. 예: ('encoder',OneHotEncoder(), [0,1,2] )
# remainder 파라미터에 passthrough 값을 입력해서 나머지 컬럼들은 그냥 통과할수있게 설정했다.
인코딩 한 후, 각 열에 있는 데이터들을 같은 범위로 맞춰주기 위해 피쳐 스케일링(feature scaling)을 해야한다.
- 표준화 (standardisation):
'평균을 기준으로 얼마나 떨어져 있는가'와 같은 기준으로 만드는 방법, 음수도 존재, 데이터의 최대최소값 모를때 사용한다.
- 정규화 (Normalisation):
0 ~ 1 사이로 맞추는 것. 데이터의 위치 비교가 가능, 데이터의 최대최소값 알떄 사용한다.

피쳐 스케일링을 하기 전 Scaler 코드를 입력하자
from sklearn.preprocessing import StandardScaler , MinMaxScaler
StandardScaler 사용:
in:
s_scaler = StandardScaler()
X = s_scaler.fit_transform(X)
Xout:
array([[ 1. , -0.57735027, -0.57735027, 0.69985807, 0.58989097],
[-1. , -0.57735027, 1.73205081, -1.51364653, -1.50749915],
[-1. , 1.73205081, -0.57735027, -1.12302807, -0.98315162],
[-1. , -0.57735027, 1.73205081, -0.08137885, -0.37141284],
[ 1. , -0.57735027, -0.57735027, -0.47199731, -0.6335866 ],
[ 1. , -0.57735027, -0.57735027, 1.22068269, 1.20162976],
[-1. , 1.73205081, -0.57735027, 1.48109499, 1.55119478],
[ 1. , -0.57735027, -0.57735027, -0.211585 , 0.1529347 ]])
MinMaxScaler 사용:
in:
m_scaler = MinMaxScaler()
X = m_scaler.fit_transform(X)
Xout:
array([[1. , 0. , 0. , 0.73913043, 0.68571429],
[0. , 0. , 1. , 0. , 0. ],
[0. , 1. , 0. , 0.13043478, 0.17142857],
[0. , 0. , 1. , 0.47826087, 0.37142857],
[1. , 0. , 0. , 0.34782609, 0.28571429],
[1. , 0. , 0. , 0.91304348, 0.88571429],
[0. , 1. , 0. , 1. , 1. ],
[1. , 0. , 0. , 0.43478261, 0.54285714]])# 둘중 하나를 선택해서 활용하면된다.
# y와 같이 이미 0과 1로만 데이터가 구성되어있으면 피쳐 스케일링을 할 필요가 없다.
만약 y 가 특정값으로 설정된 경우에는 2차 배열로 만들어야 스케일링이 가능하다.
y = y.values.reshape(9,1)
y = scaler.fit_transform(y)
※ 스케일러에 inverse_transform을 사용하면 원래값을 알수있다.
scaler_y.inverse_transform(y_pred)
이제 Dataset을 Training 용과 Test용으로 나눈다.
다음 코드를 임포트하자
from sklearn.model_selection import train_test_split
train_test_split함수를 통해 학습용과 테스트용 데이터로 나누자
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size= 0.2 , random_state=3)# 학습용 중 X_train이 학습문제 X_test은 그 답이다.
# y는 시험 문제와 답으로 볼수있다.