[파이썬] 데이터 분석 실습: 범죄현황 + 구글 맵 API (Geocoding), gmaps.geocode
서울시 구별 범죄 발생과 검거율 데이터 분석
'서울시 관서별 5대 범죄 발생 검거 현황' 파일을 가지고 분석한다.
실습 1. crime_in_Seoul.csv 파일을 pandas 로 읽어오세요.

실습 2. 경찰서들은 하나의 구에 여러개가 있을 수 있습니다. 따라서 구 단위로 데이터를 통합하세요.
구글 맵 API 를 이용해서, 경찰서가 무슨 구에 있는지 확인하기 위해 아나콘다 프롬프트웨어 다음을 실행. (pip install googlemaps)
import googlemaps# 아나콘다 기준으로 아나콘다 프롬프트를 실행하여 pip install googlemaps 입력
구글 클라우드의 MAPS API 페이지로 이동하여, API 키를 생성합니다.
https://cloud.google.com/maps-platform/?hl=ko
콘솔로 이동 => Geocoding API 선택 => 사용자인증정보 에서 API 키 생성
구글 맵스를 사용해서 경찰서의 위치(위도, 경도) 정보를 받아온다.

# api를 통해 주고받은 데이터를 json 이라고 한다.
주소에 해당되는 인덱스를 찾는다.
참고사이트: https://jsoneditoronline.org/

관서명 컬럼에 있는 값들을 가져와서 왼쪽에는 서울, 오른쪽에는 경찰서라고 붙인다.
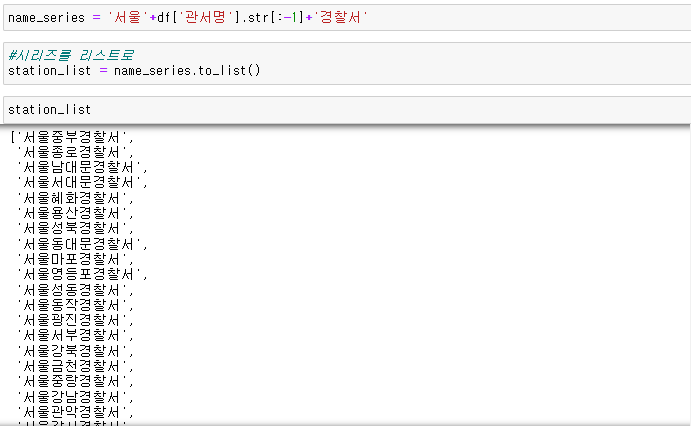
station_names 리스트에 있는 경찰서 명칭을 구글맵api에 넣어서 호출한다.

# 종암경찰서가 이전하여 구글에 주소가 나오지 않았다
# 때문에 글자수가 0인 데이터는 제외하도록 조건문을 설정했다.
실습 3. station_addreess 에 저장된 주소에서, 구만 따로 띄어냅니다. (예, 종로구)
따로 띄어낸 구를, crime_anal_police 에 '구별' 컬럼을 만들어서 넣습니다.

실습 4. 인덱스를 '구별' 로 피봇팅 한다.

실습 5. '강간검거율' , '강도검거율', '살인검거율', '절도검거율', '폭력검거율' 을 계산하여, crime_anal에 각 컬럼을 추가한다. ( 검거율은 * 100 까지 한 값)

실습 6. 이제 필요없는, '강간 검거' , '강도 검거', '살인 검거', '절도 검거', '폭력 검거' 컬럼을 제거한다.
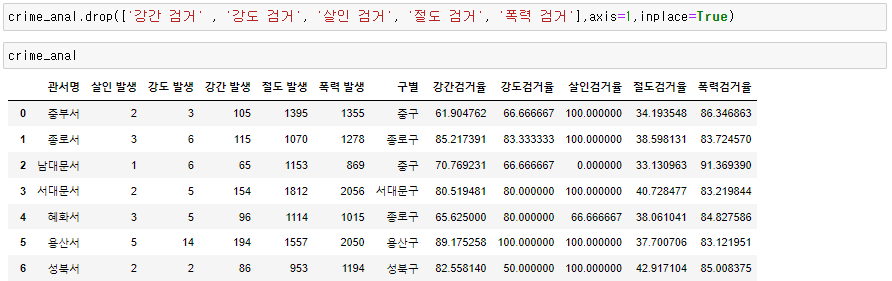
실습 7. describe() 함수로 값을 확인해 보니, 검거율이 100 이상인 경우도 있다. 따라서 100보다 크면, 100으로 값을 셋팅하세요.

# 작년에 발생한 범죄를 올해 검거하여 100이 넘어갈수 있다.
혹은 loc함수를 활용할수 있다.
crime_anal.loc[crime_anal['강간검거율']>100,'강간검거율'] = 100
실습 8. 강간 발생, 강도 발생, 살인 발생, 절도 발생, 폭력 발생 의 컬럼 명을, 강간, 강도, 살인, 절도, 폭력으로 rename 하세요.
crime_anal.rename(columns={'강간 발생':'강간', '강도 발생':'강도', '살인 발생':'살인', '절도 발생':'절도', '폭력 발생':'폭력'},inplace=True)
실습 9. 강간, 강도, 살인, 절도, 폭력 을 노멀라이징 합니다.

# 데이터 노멀라이징 하는 이유는, 각각의 레인지를 통일하여, 해석하기 쉽게 하기 위함이다.
실습 10. 강간, 강도, 살인, 절도, 폭력 의 값을 모두 더하고, 이 더한값을 '범죄' 라는 컬럼을 만들어서 넣습니다.
crime_anal['범죄'] = crime_anal['강도']+crime_anal['강간']+crime_anal['살인']+crime_anal['절도']+crime_anal['폭력']
crime_anal = pd.merge(crime_anal,df_CC, on='구별')

실습 11. '강간검거율','강도검거율','살인검거율','절도검거율','폭력검거율' 의 값을 모두 더하고, 이 더한값을 '검거' 라는 컬럼을 만들어서 넣습니다.
crime_anal['검거'] = crime_anal['강도검거율']+crime_anal['강간검거율']+crime_anal['살인검거율']+crime_anal['절도검거율']+crime_anal['폭력검거율']
실습 12. sb의 pairplot 으로 "강도", "살인", "폭력" 을 나타내세요. (연관성 확인)

# 그래프를 보니 셋 모두 정비례관계에 있다.
실습 13. x_vars는 "인구수", "CCTV" 를, y_vars는 "살인", "강도"로 pariplot을 나타내고, 연관성을 확인하세요.

실습 14. x_vars는 "인구수", "CCTV" 를, y_vars는 "살인검거율", "폭력검거율"로 pariplot을 나타내고, 연관성을 확인하세요.

# kind 파라미터를 추가해 kind='reg'를 설정하면 관계를 쉽게 볼수있는 선이 생긴다.
실습 15. x_vars는 "인구수", "CCTV" 를, y_vars는 "절도검거율", "강도검거율"로 pariplot을 나타내고, 연관성을 확인하세요.

실습 16. 검거가 가장 높은 구는 어디입니까? 이를 확인하기 위해, 검거가 가장 높은 구부터 정렬하여 5개의 구까지 나타내세요.

실습 17. 검거가 가장 큰값이 432.593167 입니다. 검거의 값이 최대가 100이 되도록 정규화를 하세요. 그리고 검거값으로 정렬하세요.

실습 18. sb.heatmap 을 이용해서 '강간검거율', '강도검거율', '살인검거율', '절도검거율', '폭력검거율' 을 보여주세요. 단, '검거' 로 정렬한 데이터로 보여주세요.

# cmap 파라미터로 색상을 재설정했다.
# annot 파라미터로 어떤 데이터를 다루고있는지 확인할수 있도록 x축 데이터의 이름을 나타냈다.
# fmt 파라미터로 수치데이터의 포맷을 소수점 한자리까지 표시했다.
# linewidths 파라미터로 각 차트 바와의 간격을 설정해줬다.
실습 19. 위에서 배운 히트맵을 이용해서, 살기 무서운 구가 어디인지 분석하세요.
